Spark 任务调度
概述
主要分为以下四个部分:
1、构建DAG
提交的 job 将首先被转化为RDD并通过RDD之间的依赖关系构建DAG,提交到调度系统2、切分stage
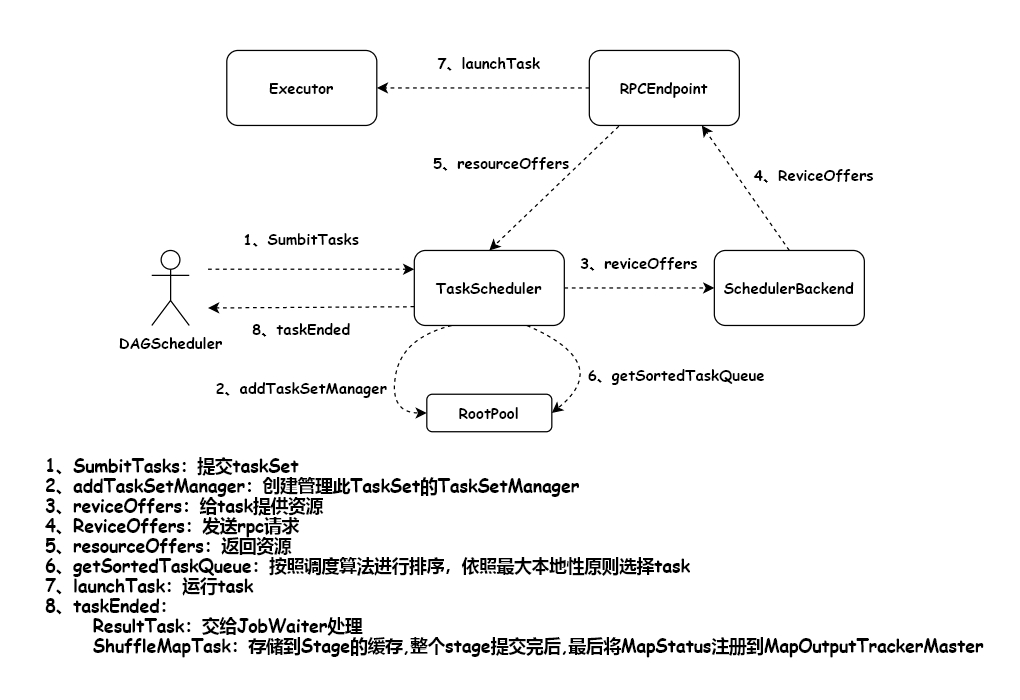
DAGScheduler负责接受由RDD构成的DAG,将一系列RDD划分到不同的Stage(ResultStage和ShuffleMapStage两种),给Stage中未完成的Partition创建不同类型的task(ResultTask和ShuffleMapTask),DAGScheduler最后将每个Stage中的task以TaskSet的形式提交给TaskScheduler继续处理。3、调度task
TaskScheduler负责从DAGScheduler接受TaskSet,创建TaskSetManager对TaskSet进行管理,并将TaskSetManager添加到调度池,最后将对Task调度提交给后端接口(SchedulerBackend)处理。4、执行task
执行任务,并将任务中间结果和最终结果存入存储体系。
Task 本地行级别
获取task的本地性级别时,都会等待一段时间,超过时间会退而求其次。
- 1、PROCESS_LOCAL(本地进程)
- 2、NODE_LOCAL(本地节点)
- 3、NO_PREF(没有最佳位置)
- 4、RACK_LOCAL(本地机架)
- 5、ANY(任何)
TaskSchedulerImpl调度流程
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Asura7969 Blog!










